问题描述
我使用AICube训练OCR识别模型,导出后mp source里的内容如图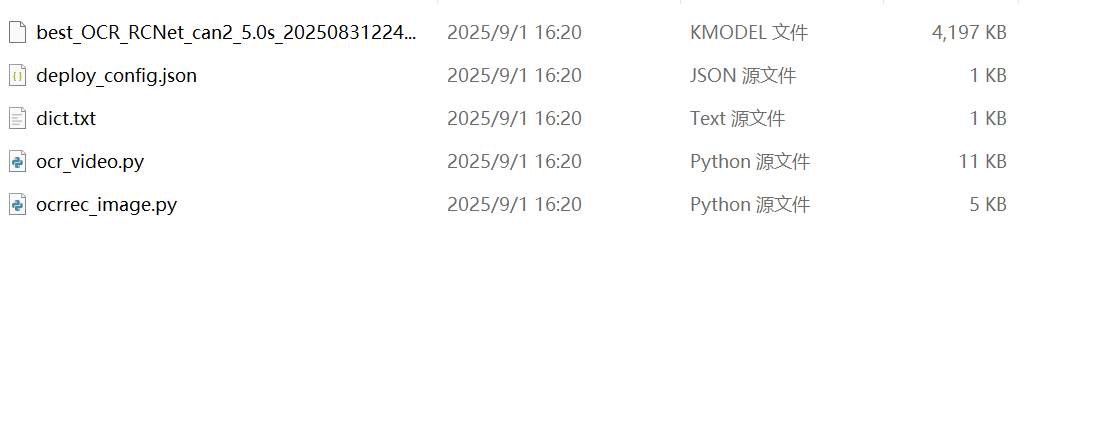
但没有在ocr_video.py中要的ocrdet和ocrrec的json文件,如下:
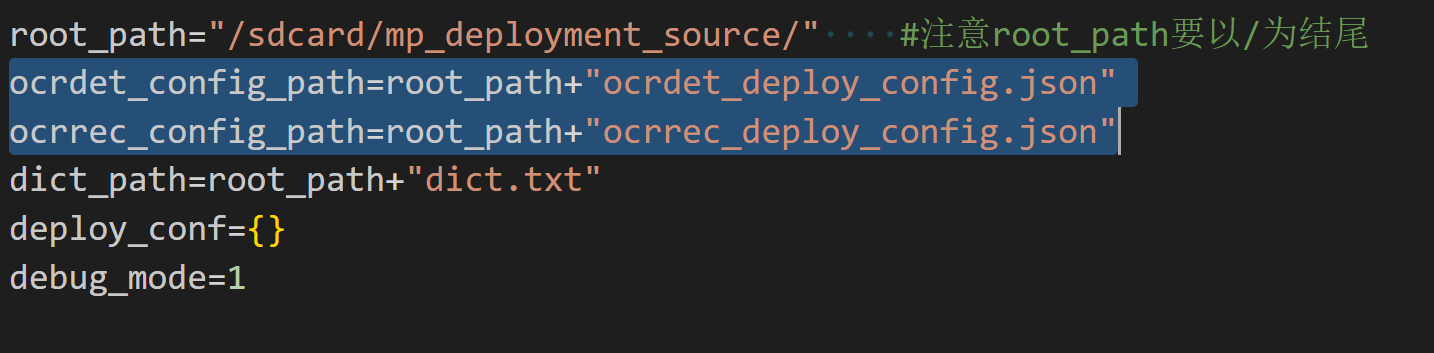
这是为什么?
训练了官方的OCR识别demo也出现同样的问题
硬件板卡
庐山派
软件版本
CanMV_K230_LCKFB_micropython_v1.3-0-g8dd764f_nncase_v2.9.0
我使用AICube训练OCR识别模型,导出后mp source里的内容如图
但没有在ocr_video.py中要的ocrdet和ocrrec的json文件,如下:
这是为什么?
训练了官方的OCR识别demo也出现同样的问题
庐山派
CanMV_K230_LCKFB_micropython_v1.3-0-g8dd764f_nncase_v2.9.0
你好,完整的OCR任务需要包含两个步骤,两个模型,一般是先从画面中检测出文本区域,以文本框的形式输出,然后再对文本框内的内容进行识别,你应该先训练一个检测模型,再训练一个识别模型实现完整的ocr任务。ocr识别任务的输入一般都是检测后长条状的文本行,所以不太适合视频推理,这里没有给出ocrrec任务视频识别的脚本,只给出了ocrrec_image的图片推理脚本,和两阶段ocr完整的推理脚本。
