问题描述
训练用到的数据集是从CCPD2019、2020里边随机挑出来的图片,总共3312张。

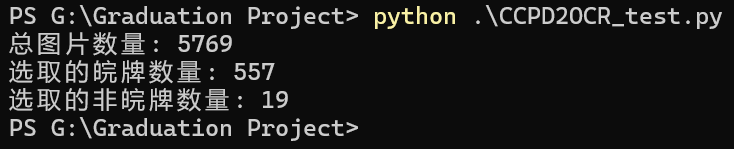
转换的标注信息也确认无误,但是OCR识别训练的效果非常差,虽然挑选了全部非皖牌图片,但是仍然难以识别除皖牌以外的车牌信息,而且对于字母和数字识别效果也不好。
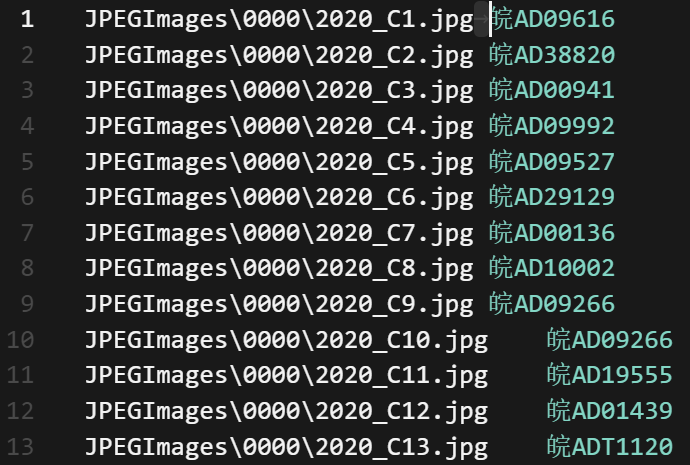
下面是我转换出来的OCR识别标注信息,虽然有几行看着是空格的间距但是实际上是tab缩进,不太清楚为什么,不过无论是上传到在线训练平台还是AI CUBE里面都能准确对应上就没管了。
皖牌:
非皖牌:
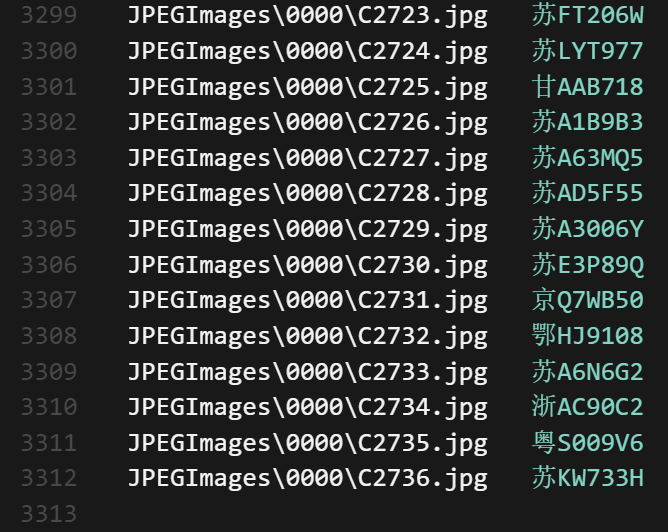
图片我是直接用的CCPD原本的图片,有各种情况下的车牌,但是都没有把车牌部分单独裁剪出来,不知道是不是车牌占图片比例太小导致的效果不佳,但是这样应该也只是会延长模型拟合的时间吧?会对识别精度造成影响吗?
看了AI CUBE用户指南以及CanMV K230开发文档选择的训练模型。
一开始试过RLnet+0.5宽度can3_large+Chinese预训练,识别效果不太行:字符识别错误、字符识别数量不符、训练<Acc40%、评估那边的测试结果也是0
现在换成RLnet+1.0宽度can2+无预训练,练了两次150迭代虽然训练Acc能爬上50%,但是验证Acc一直是0%(我从上手训练到现在还没见过这个数有变化😭)
训练过程(右边验证图片放大过,原本很小一张):
当前训练是已经经过两次150次迭代的模型
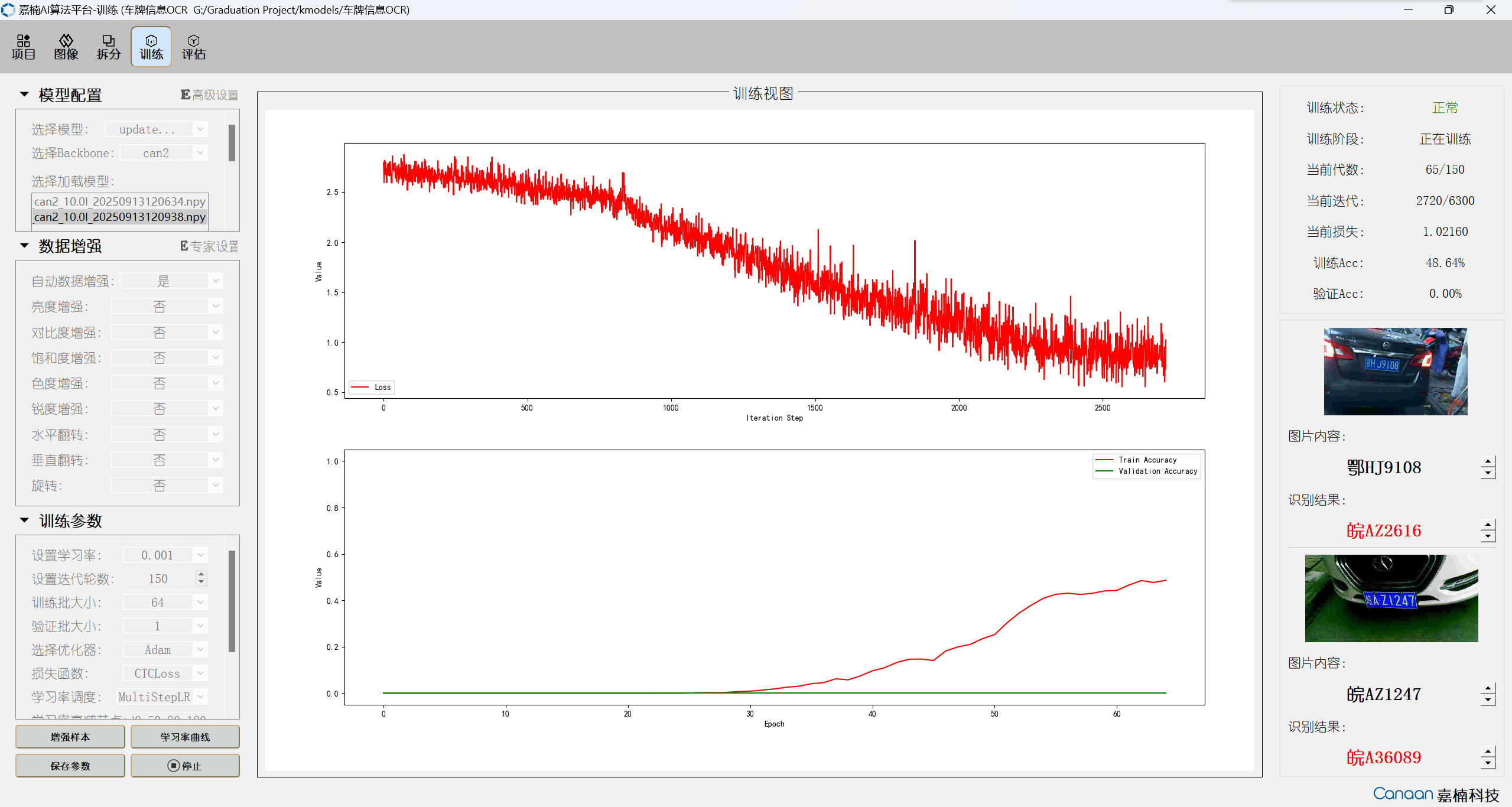
想了解下数据集是否需要把车牌区域单独抠出来,如果要的话有没有现成的数据集呢?如果不用的话应该怎么修改参数,还是说继续练就行?
下表是当前训练设置的详细参数
| 参数名称 | 当前设置参数 |
|---|---|
| 训练模型 | OCR_RLnet |
| backbone | can2 |
| 预训练 | 否(试过chinese模型,对中文识别也是不太准确) |
| 模型宽度 | 1.0 |
| 图像尺寸 | 宽 60×4 高 2×32 |
| 是否定长 | 是 |
| 自动数据增强 | 是 |
| lr | 0.001 |
| max_batches | 150 |
| train_batches | 64 |
| val_batches | 1 |
| 优化器 | Adam(查了下其他几个感觉好像差不多) |
| lr衰减节点 | 20,50,80,120 |
| lr衰减因子 | 0.30 |
| 刷新损失步长 | 5 |
| GPU索引 | 0 |
硬件信息:
- 系统:WIN11_24H2
- 内存:32GB DDR5 4800MHZ
- 显卡:RTX 3060 Laptop 6GB(已安装CUDA及cuDNN)
AI CUBE:v1.4版本
谢谢
软件版本
AI CUBE_v1.4 CUDA_v12.4 cuDNN_v9.10.0

