问题描述
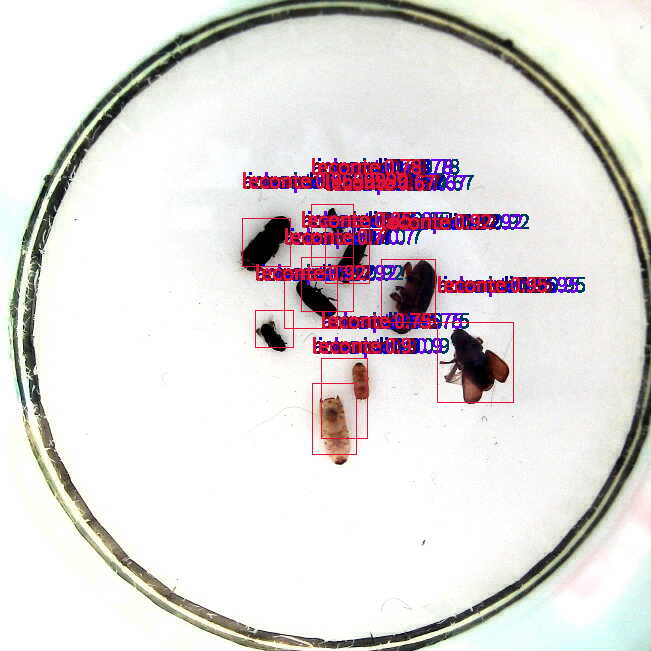
我使用AI_Cube示例数据进行训练,部署后生成的det_image.py中,每个目标的所有标签置信度都是一样的。但是我在AI_Cube模型评估中看到的测试集数据推理结果没有出现这样的问题。
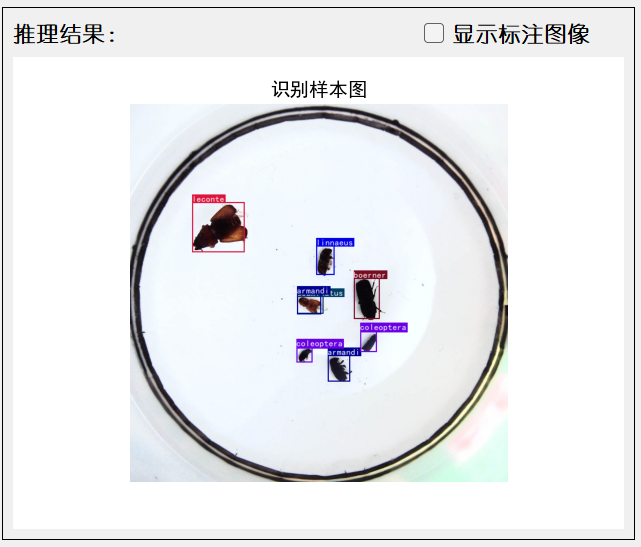
是部署出现了什么问题吗?我除了分辨率之外没有修改过生成的程序。
硬件板卡
亚博
软件版本
CanMV_K230_YAHBOOM_micropython_local_nncase_v2.9.0
其他信息
训练模型:AnchorFreeDet,其余参数为默认
我使用AI_Cube示例数据进行训练,部署后生成的det_image.py中,每个目标的所有标签置信度都是一样的。但是我在AI_Cube模型评估中看到的测试集数据推理结果没有出现这样的问题。
是部署出现了什么问题吗?我除了分辨率之外没有修改过生成的程序。
亚博
CanMV_K230_YAHBOOM_micropython_local_nncase_v2.9.0
训练模型:AnchorFreeDet,其余参数为默认
你好,排查后发现确实存在一些问题:
https://kendryte-download.canaan-creative.com/developer/releases/canmv_k230_micropython/daily_build/选择对应的开发板的固件下载烧录,使用cv_lite模块加载图片,使用openmv的image模块可能会有问题;



这里把测试代码也附上:
import os
import ujson
import aicube
from media.sensor import *
from media.display import *
from media.media import *
from time import *
import nncase_runtime as nn
import ulab.numpy as np
import time
import image
import random
import gc
import utime
import cv_lite
DISPLAY_WIDTH = ALIGN_UP(1920, 16)
DISPLAY_HEIGHT = 1080
color_three = [(220, 20, 60), (119, 11, 32), (0, 0, 142), (0, 0, 230),
(106, 0, 228), (0, 60, 100), (0, 80, 100), (0, 0, 70),
(0, 0, 192), (250, 170, 30), (100, 170, 30), (220, 220, 0),
(175, 116, 175), (250, 0, 30), (165, 42, 42), (255, 77, 255),
(0, 226, 252), (182, 182, 255), (0, 82, 0), (120, 166, 157),
(110, 76, 0), (174, 57, 255), (199, 100, 0), (72, 0, 118),
(255, 179, 240), (0, 125, 92), (209, 0, 151), (188, 208, 182),
(0, 220, 176), (255, 99, 164), (92, 0, 73), (133, 129, 255),
(78, 180, 255), (0, 228, 0), (174, 255, 243), (45, 89, 255),
(134, 134, 103), (145, 148, 174), (255, 208, 186),
(197, 226, 255), (171, 134, 1), (109, 63, 54), (207, 138, 255),
(151, 0, 95), (9, 80, 61), (84, 105, 51), (74, 65, 105),
(166, 196, 102), (208, 195, 210), (255, 109, 65), (0, 143, 149),
(179, 0, 194), (209, 99, 106), (5, 121, 0), (227, 255, 205),
(147, 186, 208), (153, 69, 1), (3, 95, 161), (163, 255, 0),
(119, 0, 170), (0, 182, 199), (0, 165, 120), (183, 130, 88),
(95, 32, 0), (130, 114, 135), (110, 129, 133), (166, 74, 118),
(219, 142, 185), (79, 210, 114), (178, 90, 62), (65, 70, 15),
(127, 167, 115), (59, 105, 106), (142, 108, 45), (196, 172, 0),
(95, 54, 80), (128, 76, 255), (201, 57, 1), (246, 0, 122),
(191, 162, 208)]
root_path="/sdcard/mp_deployment_source/" # root_path要以/结尾
config_path=root_path+"deploy_config.json"
image_path=root_path+"0180.jpg"
deploy_conf={}
debug_mode=1
class ScopedTiming:
def __init__(self, info="", enable_profile=True):
self.info = info
self.enable_profile = enable_profile
def __enter__(self):
if self.enable_profile:
self.start_time = time.time_ns()
return self
def __exit__(self, exc_type, exc_value, traceback):
if self.enable_profile:
elapsed_time = time.time_ns() - self.start_time
print(f"{self.info} took {elapsed_time / 1000000:.2f} ms")
def read_deploy_config(config_path):
# 打开JSON文件以进行读取deploy_config
with open(config_path, 'r') as json_file:
try:
# 从文件中加载JSON数据
config = ujson.load(json_file)
# 打印数据(可根据需要执行其他操作)
#print(config)
except ValueError as e:
print("JSON 解析错误:", e)
return config
def read_img(img_path):
# openmv image加载图片
# img_data = image.Image(img_path)
# img_data_rgb888=img_data.to_rgb888()
# img_hwc=img_data_rgb888.to_numpy_ref()
# cv_lite加载图片
img_hwc=cv_lite.load_image(img_path)[0]
print(img_hwc.shape)
shape=img_hwc.shape
img_tmp = img_hwc.reshape((shape[0] * shape[1], shape[2]))
img_tmp_trans = img_tmp.transpose()
img_res=img_tmp_trans.copy()
img_return=img_res.reshape((shape[2],shape[0],shape[1]))
return img_return
def detection():
print("--------------start-----------------")
# 使用json读取内容初始化部署变量
deploy_conf=read_deploy_config(config_path)
kmodel_name=deploy_conf["kmodel_path"]
labels=deploy_conf["categories"]
# 注意调整阈值
confidence_threshold = 0.45
nms_threshold = 0.4
img_size=deploy_conf["img_size"]
num_classes=deploy_conf["num_classes"]
nms_option = deploy_conf["nms_option"]
model_type = deploy_conf["model_type"]
if model_type == "AnchorBaseDet":
anchors = deploy_conf["anchors"][0] + deploy_conf["anchors"][1] + deploy_conf["anchors"][2]
kmodel_frame_size = img_size
strides = [8,16,32]
# ai2d输入输出初始化
ai2d_input = read_img(image_path)
frame_size = [ai2d_input.shape[2],ai2d_input.shape[1]]
ai2d_input_tensor = nn.from_numpy(ai2d_input)
ai2d_input_shape=ai2d_input.shape
data = np.ones((1,3,img_size[0],img_size[1]),dtype=np.uint8)
ai2d_out = nn.from_numpy(data)
# 计算padding值
ori_w = ai2d_input_shape[2]
ori_h = ai2d_input_shape[1]
width = kmodel_frame_size[0]
height = kmodel_frame_size[1]
ratiow = float(width) / ori_w
ratioh = float(height) / ori_h
if ratiow < ratioh:
ratio = ratiow
else:
ratio = ratioh
new_w = int(ratio * ori_w)
new_h = int(ratio * ori_h)
dw = float(width - new_w) / 2
dh = float(height - new_h) / 2
top = int(round(dh - 0.1))
bottom = int(round(dh + 0.1))
left = int(round(dw - 0.1))
right = int(round(dw + 0.1))
# init kpu and load kmodel
kpu = nn.kpu()
ai2d = nn.ai2d()
kpu.load_kmodel(root_path+kmodel_name)
ai2d.set_dtype(nn.ai2d_format.NCHW_FMT,
nn.ai2d_format.NCHW_FMT,
np.uint8, np.uint8)
ai2d.set_pad_param(True, [0,0,0,0,top,bottom,left,right], 0, [114,114,114])
ai2d.set_resize_param(True, nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel )
ai2d_builder = ai2d.build([1,3,ai2d_input_shape[1],ai2d_input_shape[2]], [1,3,height,width])
with ScopedTiming("total",debug_mode > 0):
ai2d_builder.run(ai2d_input_tensor, ai2d_out)
kpu.set_input_tensor(0, ai2d_out)
kpu.run()
del ai2d_input_tensor
del ai2d_out
# get output
results = []
for i in range(kpu.outputs_size()):
data = kpu.get_output_tensor(i)
result = data.to_numpy()
result = result.reshape((result.shape[0]*result.shape[1]*result.shape[2]*result.shape[3]))
del data
results.append(result)
gc.collect()
image_draw=image.Image(image_path).to_rgb565()
# postprocess
if model_type == "AnchorBaseDet":
det_boxes = aicube.anchorbasedet_post_process( results[0], results[1], results[2], kmodel_frame_size, frame_size, strides, num_classes, confidence_threshold, nms_threshold, anchors, nms_option)
elif model_type == "GFLDet":
det_boxes = aicube.gfldet_post_process( results[0], results[1], results[2], kmodel_frame_size, frame_size, strides, num_classes, confidence_threshold, nms_threshold, nms_option)
else:
det_boxes = aicube.anchorfreedet_post_process( results[0], results[1], results[2], kmodel_frame_size, frame_size, strides, num_classes, confidence_threshold, nms_threshold, nms_option)
if det_boxes:
for det_boxe in det_boxes:
x1, y1, x2, y2 = det_boxe[2],det_boxe[3],det_boxe[4],det_boxe[5]
w = float(x2 - x1)
h = float(y2 - y1)
image_draw.draw_rectangle(int(x1) , int(y1) , int(w) , int(h) , color=color_three[det_boxe[0]],thickness=3)
label = labels[det_boxe[0]]
score = str(round(det_boxe[1],2))
image_draw.draw_string_advanced( int(x1) , int(y1)-20,15, label + " " + score , color=color_three[det_boxe[0]])
print("\n" + label + " " + score)
image_draw.compress_for_ide()
image_draw.save(root_path+"det_result.jpg")
else:
print("No objects were identified.")
del results
del ai2d
del ai2d_builder
del kpu
gc.collect()
print("---------------end------------------")
nn.shrink_memory_pool()
if __name__=="__main__":
nn.shrink_memory_pool()
detection()
感谢大佬,其实视频流在AncherFree模型下标签参数还是重合,但是换了AncherBase之后就行了
测试图片正常说明训练没有问题,导出模型时分辨率是224*224,那训练的分辨率呢?量化的参数选择的是什么,你把生成的部署包发过来wangyan01@canaan-creative.com
你好,可以调整一下阈值试试,主要调整下面的三个参数:
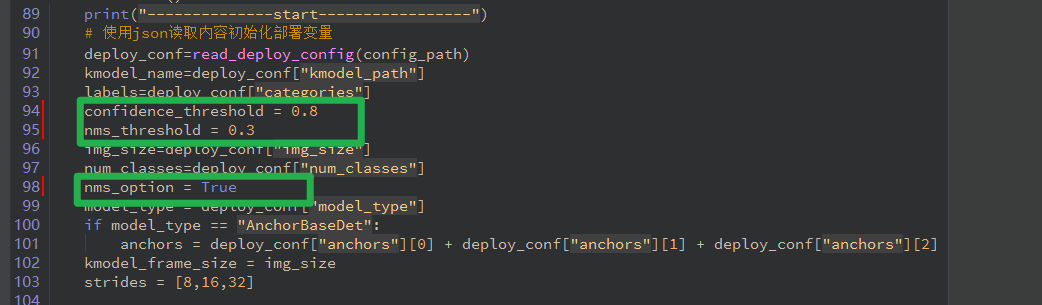



而且不只是置信度,aicube.anchorfreedet_post_process输出的det_boxes只有[0]是不一样的,也就是只有tag不一样,其它参数都输出一样的。
分辨率改成多少了
部署时推理宽高是224*224